HDFS 常用命令与初体验
本文最后更新于:2 年前
HDFS 命令
文件目录的创建
1 | |
| 参数 | 功能 |
|---|---|
| -p | 可以创建不存在的多级目录 |
创建 /park01目录
1
hdhdfs dfs -mkdir /park01创建 /park02/park03 多层目录
1
h dfs dfs -mkdir -p /park02/park03创建 /park04/park05 多个目录
1
hdfs dfs -mkdir /park04 /park05
文件上传与下载
上传本地文件到 HDFS
copyFromLocal 命令
1 | |
| 常用参数 | 功能 |
|---|---|
| -f | 强制上传。如果目标路径中已经存在同名文件,则直接覆盖 |
将 test 目录的 a.txt 上传到 /park01 目录下


将 a.txt 重新上传到 /park01 目录(后上传的会覆盖先上传的)

put 命令
1 | |
| 常用参数 | 功能 |
|---|---|
| -f | 强制上传。如果目标路径中已经存在同名文件,则直接覆盖 |
将 test 目录的 c.txt 上传到 /park02 目录下


下载 HDFS 文件到本地
copyFromLocal 命令
1 | |
| 常用参数 | 功能 |
|---|---|
| -p | 上传文件时保留原来的访问、修改时间、所有权和权限 |
从 HDFS 的 /park01 目录下载 b.txt 到 test 目录

从 /park01 目录下载 b.txt 并重命名为 c.txt

get 命令
1 | |
从 /park01 目录下载 b.txt 并重命名为 d.txt

目录信息的查看
1 | |
| 常用参数 | 功能 |
|---|---|
| -d | 只显示指定目录的属性内容 |
| -h | 将目录下的文件大小以人类认识的方式显示(例如:10.4 K,而不是10679) |
| -R | 递归显示子孙目录的内容 |
查看 根目录 / 的信息,并递归显示子目录.

文件内容的查看
cat指令:
查看指定文件内容
1 | |
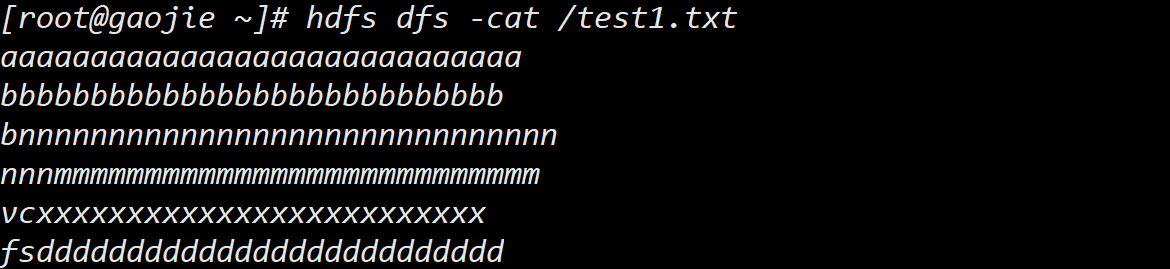
查看 /test1.txt 中内容
tail指令
显示文件的最后 1KB 的数据
1 | |
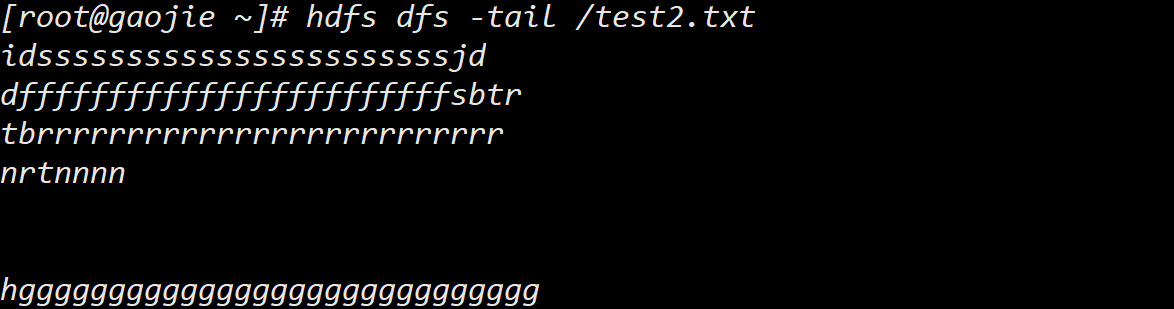
- 查看文件 /test2.txt 最后 1KB 的数据
Hadoop 初体验
执行 Hadoop 官方自带的 MapReduce 案例:
评估圆周率 π
进入到 …/hadoop-2.7.3/share/hadoop/mapreduce 目录下,执行以下命令:


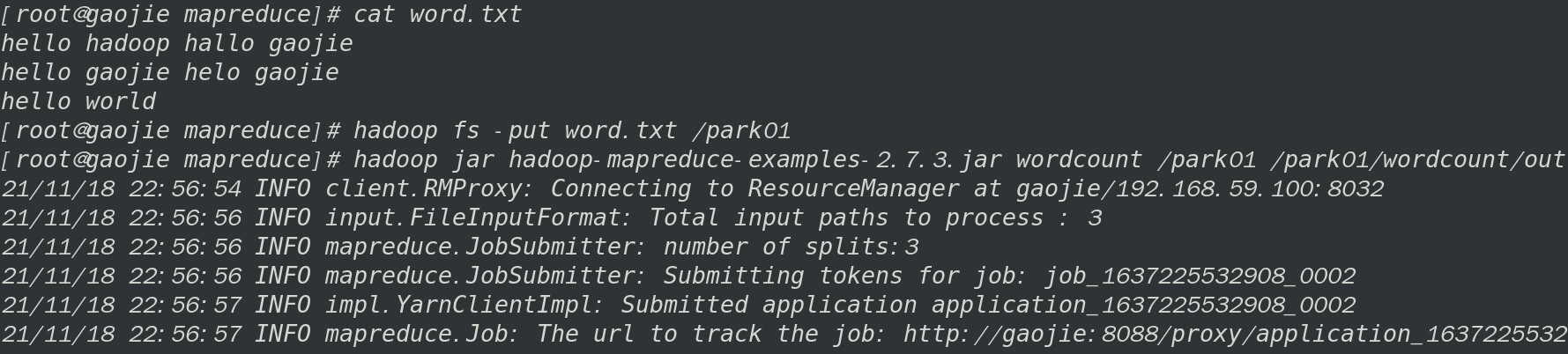
词频统计




MapReduce 本质是一个程序。
执行 MapReduce 的时候,首先请求 YARN ,因为需要 YARN 来管理计算机资源。
MapReduce 看起来似乎有两个阶段,而且是先 Map,后 Reduce。
处理小数据时,MapReduce 似乎很慢。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!