Hadoop 伪分布式安装
本文最后更新于:2 年前
1. 关闭防火墙
- 查看防火墙状态:
systemctl status firewalld
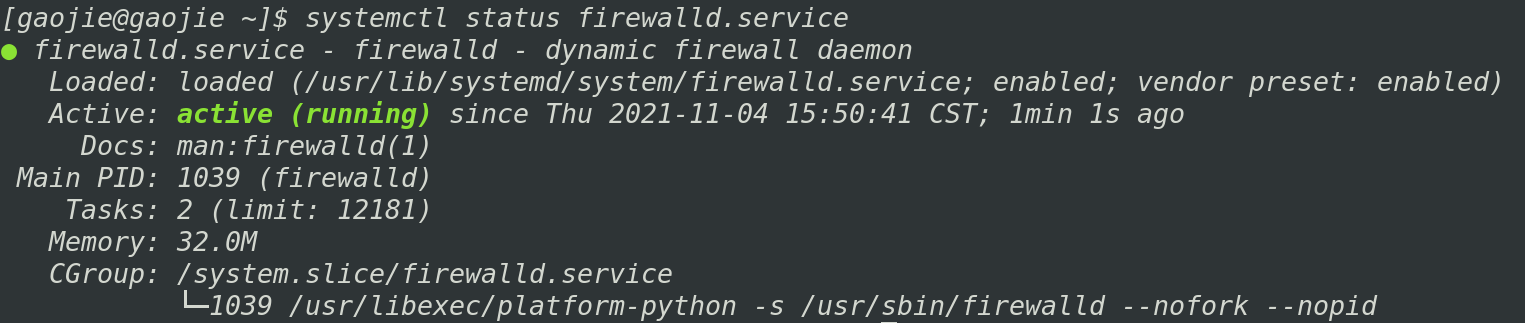
- 关闭防火墙:
systemctl stop firewalld

- 在开机时禁用防火墙:
systemctl disable firewalld

2. 配置hosts文件
使用 vim 命令编辑 /etc/hosts配置文件

在文件最后一行添加如下内容:

配置完以后 ip 地址可以用 gaojie 代替。
3. 开启免密登录
输入
ssh-keygen -t rsa命令,然后一路回车,生成密钥: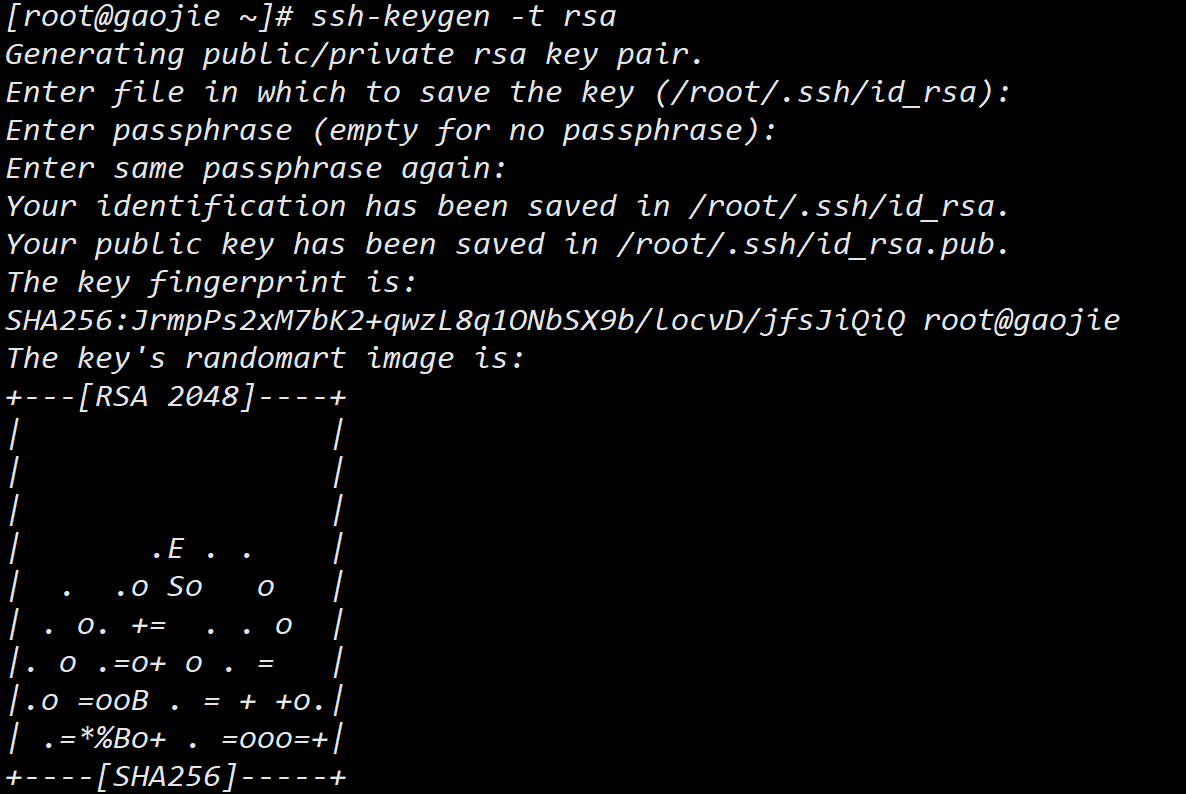
使用
ssh-copy-id root@gaojie命令复制密钥:
4. 上传安装包
在有网络前提下,可以使用 yum 安装 lrzsz软件 ,直接将本机文件拖入 linux 命令行即可上传文件。
没有网络连接,可以使用 filezilla 或 Xftps上传安装包。
添加 hadoop-2.7.3.tar.gz 和 jdk-8u11-linux-x64.tar.gz 到 /home/software 目录:


5. 安装配置jdk
使用
tar命令,解压安装包:1
2tar -zxvf hadoop-2.7.3.tar.gz
tar -zxvf jdk-8u11-linux-x64.tar.gz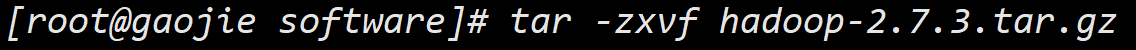


编辑 /etc/profile 配置文件,配置环境变量

在尾部追加如下内容,配置 java 的环境变量:
1
2
3
4#hadoop配置
export JAVA_HOME=/home/software/jdk1.8
export PATH=$JAVA_HOME/bin:$PATH:$HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar一般模式下,按
G可快速定位到最底部,按$可快速定位到行末。
使用命令
source /etc/profile使配置文件立即生效:
配置成功,查看 jdk 版本信息:
ava -version
编写一个 Hello.java 程序,可以正常运行:

6. 配置Hadoop

配置 HDFS
1. 配置 hadoop-env.sh
进入hadoop安装路径下的 etc/hadoop 目录,利用 vim进行编辑:

分别在 24 行、33行 修改为如下内容:
1 | |
一般模式下,敲 24+回车 即可定位到 24行。
2. 配置 core-site.xml
使用 vim 编辑: vim core-site.xml

添加如下内容:
1 | |
其中,第一个 value 是用主机名代替的 ip 地址;第二个 value 中填写的 tmp/ 目录是自己手动创建的,用来存储 hadop 运行时产生的文件。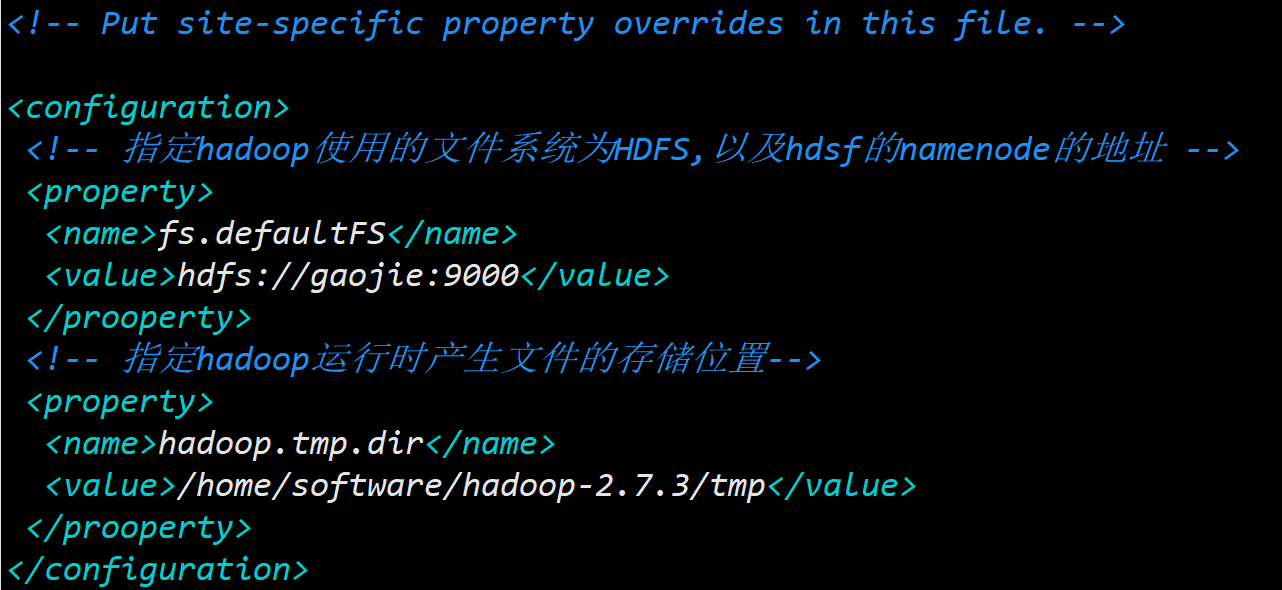
3. 配置 hdfs-site.xml
使用 vim 编辑: vim hdfs-site.xml
添加如下内容:
1 | |
4. 配置 /etc/profile 环境变量
编辑 /etc/profile 配置文件,添加 hadoop 的环境变量:

使用 source /etc/profile命令 使配置文件立即生效 。

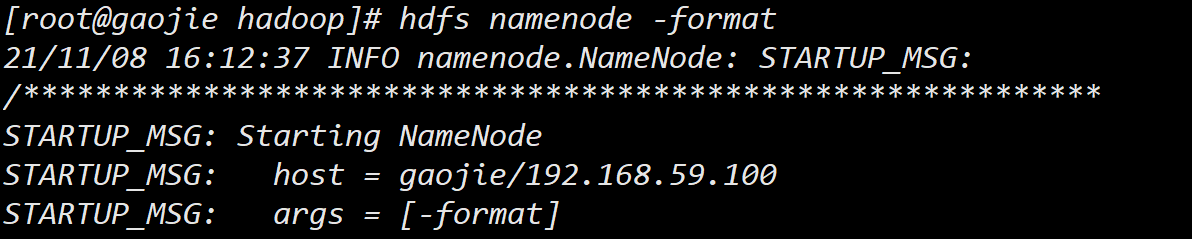
5. 检验 hdfs
配置完 hdfs 后,需要在第一次启动时进行格式化操作,用于生成 hdfs文件系统的系统文件:
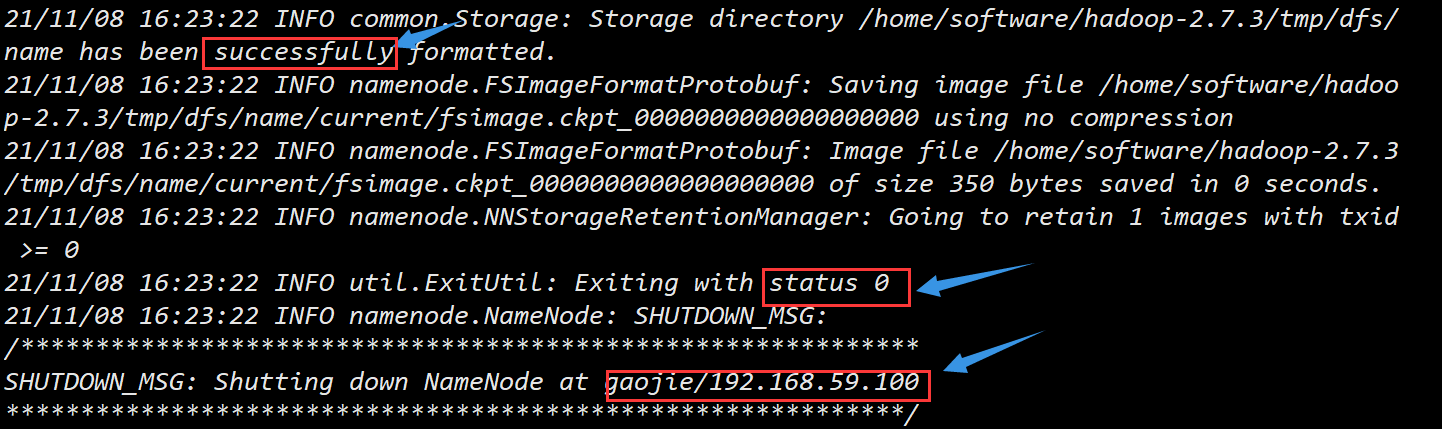
看到以下信息表示格式化成功:
启动 hdfs:

检验是否配置成功:jps

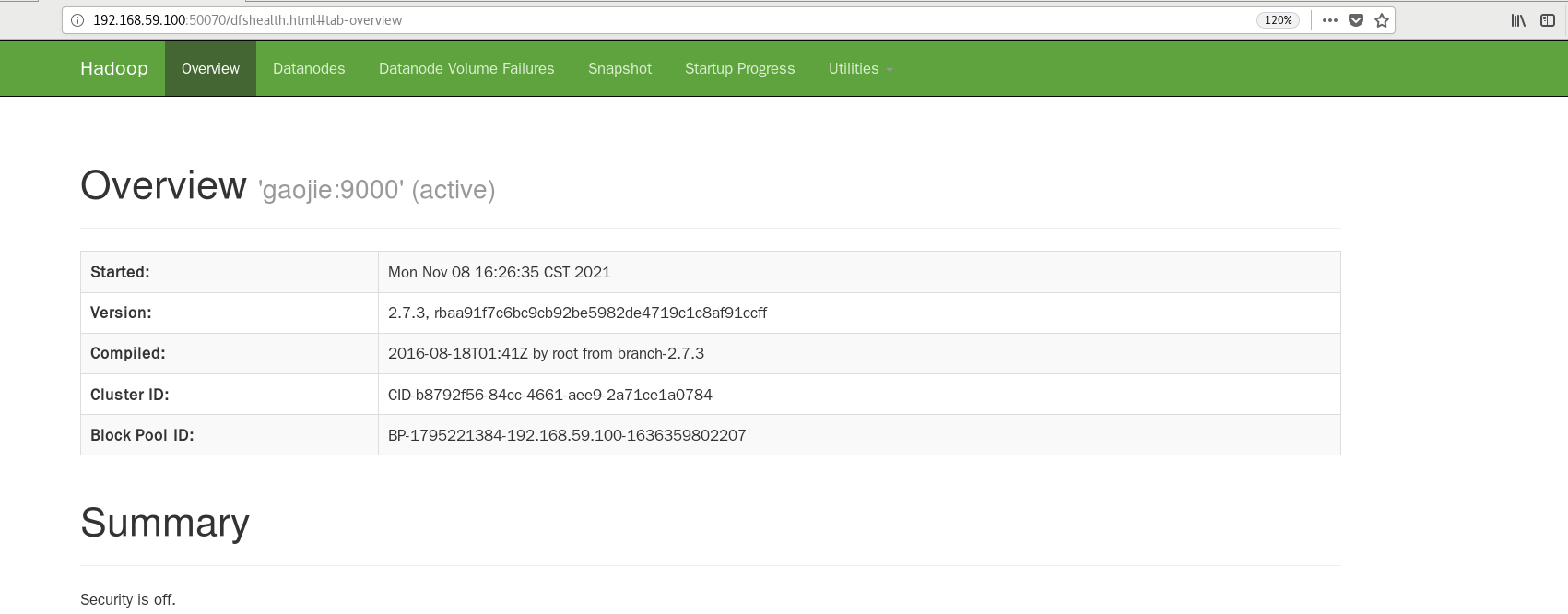
访问web界面:
关闭 hdfs:

配置 MapReducer
1. 配置 mapred-site.xml
该文件原本不存在,只有模板文件,通过cp命令复制:
1 | |
复制后使用 vim 编辑该文件:vim mapred-site.xml
修改如下内容:
1 | |
2. 配置 yarn-site.xml
使用 vim yarn-site.xml 指令编辑 yarn-site.xml 文件,修改如下内容:
1 | |
3. 检验MapReduce
启动 MapReduce :
start-yarn.sh如果配置成功,启动 MapReduce 后可以通过 192.168.59.100:8088(Ip+端口号8088),访问 MapReduce 的 Web 界面:
关闭 MapReduce:
stop-yarn.sh
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!