Spring简介:特性与架构详说明 传统web程序及缺点传统程序开发步骤 传统web项目开发中的耦合度问题 在 Servlet 中调用 service 中的方法,则需要在Servlet类中通过new关键字创建Service的实例: 123public interface ProductService{ public List<Product> listProducts();} 12345pub 2022-03-12 SSM框架 Spring Spring
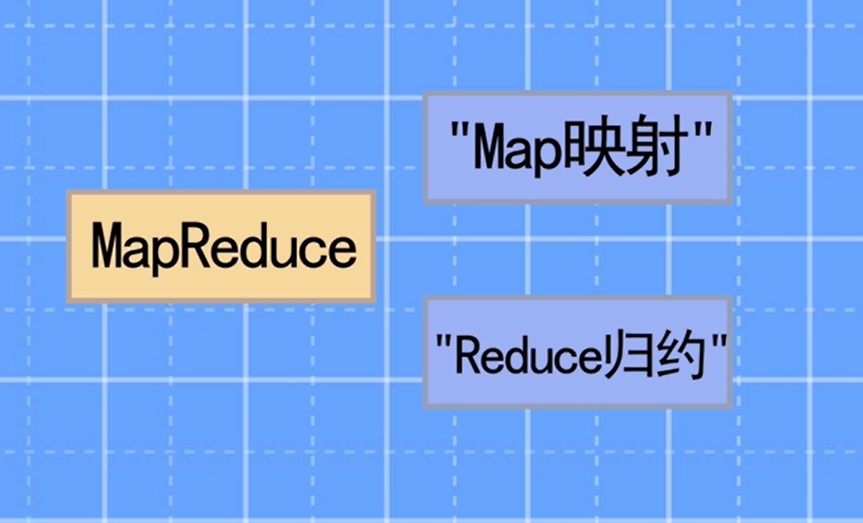
Mapreduce模型、核心思想、构思及编程规范 MapReduce 简介MapReduce 是分布式并行计算框架,用来进行大规模数据集计算(大于1TB)。分布式程序运行在大规模的计算机集群中,可以并行执行大规模处理任务,从而获取海量的计算能力。 核心思想MapReduce 的思想核心是 “分而治之”,适用于大量复杂的任务处理场景(大规模数据处理场景)。它将运行在大规模集群中的复杂的并行计算的过程抽象成了两个方法:map 和 reduce。 M 2022-03-11 Hadoop大数据高级开发 Mapreduce
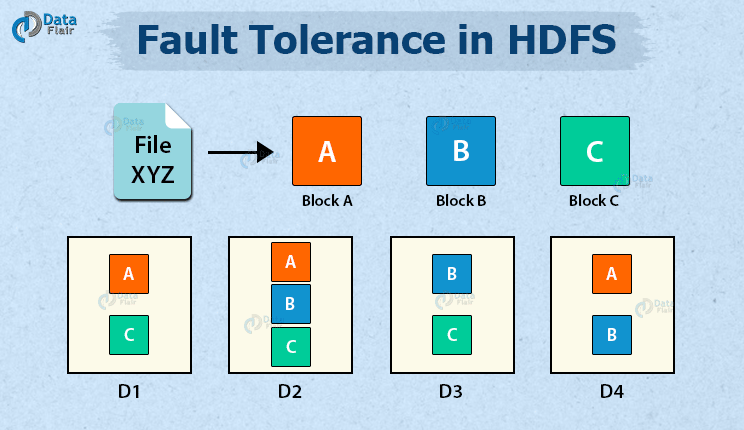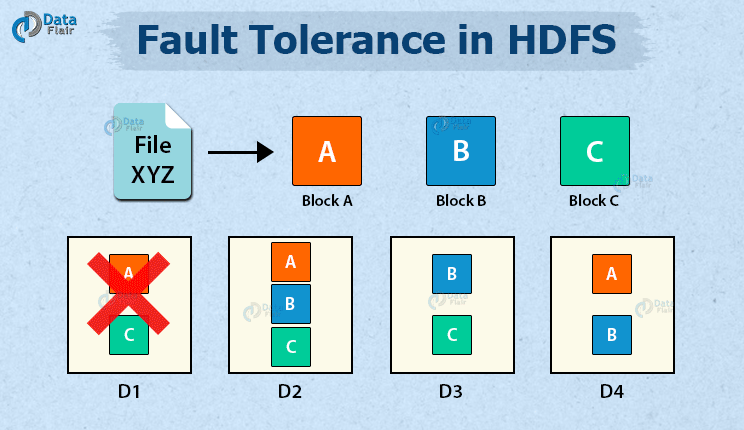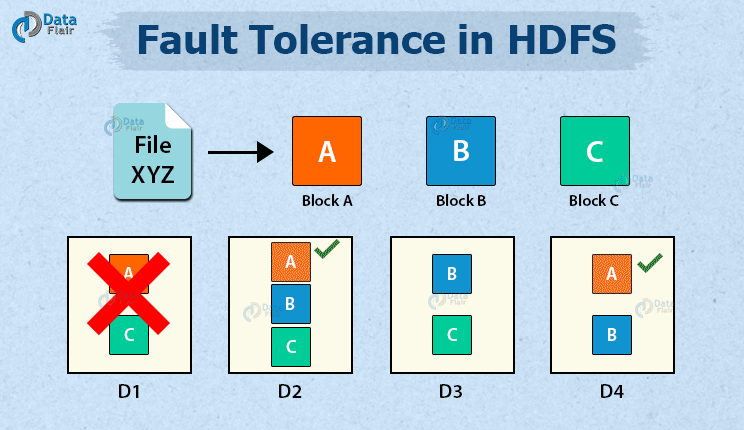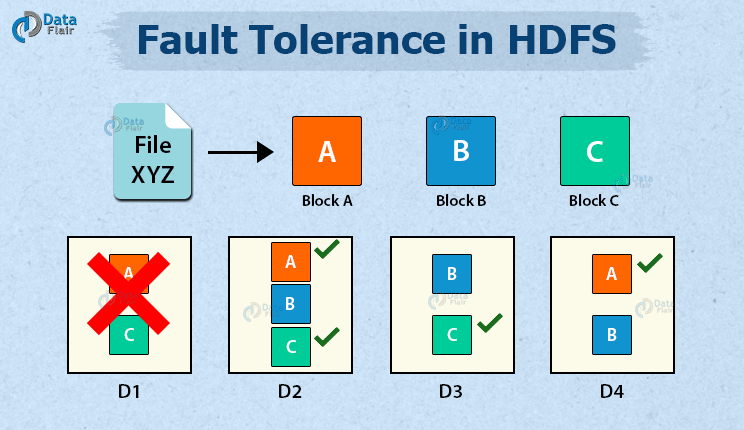
HDFS文件操作流程 读/下载流程 客户端向 NameNode 发起请求; NamaNode 接收到请求后,会进行校验; 客户端是否有读取权限 是否存在指定文件 如果校验失败,则直接报错;如果校验成功,那么 NameNode 向客户端返回信号允许读取; 客户端接收到信号,会再次发起请求,请求获取第一个 block 的存储地址; NameNode 接收到信号后,会查询元数据,这个 block 的存储地址会被放 2022-03-11 Hadoop大数据高级开发 Hadoop
Log4j的简单使用 Log4j 简介Log4J 是 Apache 的一个开源项目。通过在项目中使用 Log4J,我们可以控制日志信息输出到控制台、文件、GUI 组件、甚至是数据库中。我们可以控制每一条日志的输出格式,通过定义日志的输出级别,可以更灵活的控制日志的输出过程。方便项目的调试。 官网:https://logging.apache.org/log4j/2.x/ 三大组件Log4J 主要由 Logger (日志 2022-03-10 Log4j
使用 Hadoop API 操作HDFS文件系统 HDFS 在生产应用中主要是 Java 客户端的开发,其核心步骤是从 HDFS 提供的 API 中构造一个 HDFS 的访问客户端对象,然后通过该客户端对象操作(增删改查)HDFS 上的文件。 客户端核心类: Configuration :配置对象类,用于加载或设置参数属性。 FileSystem:文件系统对象基类,针对不同文件系统有不同具体实现。该类封装了文件系统的相关操作方法。 API 核 2022-03-10 Hadoop大数据高级开发 Hadoop
Django模型操作数据库 通过ORM操作数据库Django 提供了一个数据库抽象API,可以查询、添加、更新和删除数据。实现了 ORM 功能,在 Django 项目中,不需要写sql语句,通过模型类和对象,就可以直接操作数据库数据了。 可以通过以下命令,进入python交互环境,执行操作数据库的代码: 1python manage.py shell 查询数据每个模型类默认都有 objects 类属性,可以把它叫 模型管理 2022-03-08 Python Web 开发 Django SQL
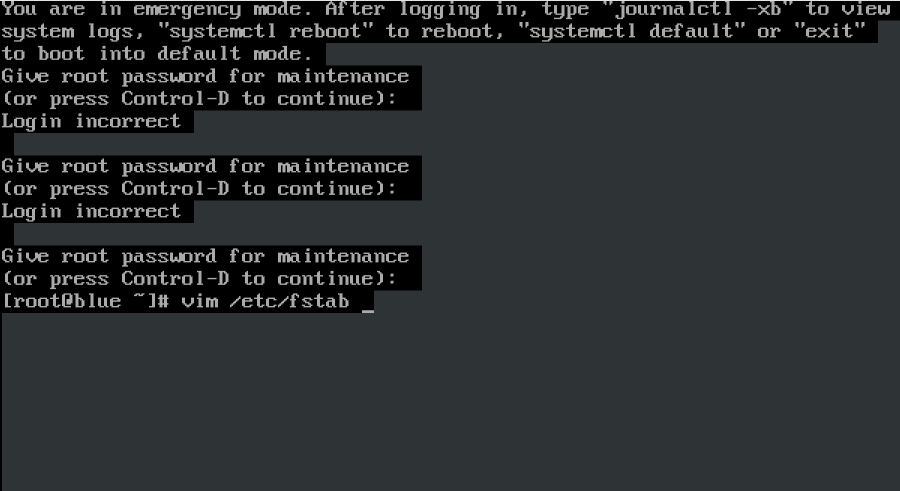
Linux中几种/etc/fstab常见错误解决方案 设备异常挂载常见原因 可能是没有设备 可能有设备,没有分区 可能有设备,有分区,但是后来做其他实验,删除了分区 设备有,分区有,/etc/fstab文件字母错误 场景模拟假设计算机中没有 sde 设备,也没有该设备的分区,但 /etc/fstab 中最后一行有如下错误挂载信息: 此时重启虚拟机,会进入救援模式,不能正常启动: 异常分析计算机没有 sde 设备,更没有分区,而计算机开机 2022-03-08 Linux RHCSA
HDFS 常用命令与初体验 HDFS 命令文件目录的创建1hdfs dfs -mkdir [-p] <path> ... 参数 功能 -p 可以创建不存在的多级目录 创建 /park01目录 1hdhdfs dfs -mkdir /park01 创建 /park02/park03 多层目录 1h dfs dfs -mkdir -p /park02/park03 2022-03-05 Hadoop大数据高级开发 Hadoop
Hadoop 伪分布式安装 1. 关闭防火墙 查看防火墙状态:systemctl status firewalld 关闭防火墙:systemctl stop firewalld 在开机时禁用防火墙:systemctl disable firewalld 2. 配置hosts文件 使用 vim 命令编辑 /etc/hosts配置文件 在文件最后一行添加如下内容: 配 2022-03-05 Hadoop大数据高级开发 Hadoop
大数据及 Hadoop 简介 大数据常用名词 数据挖掘:data mining。简单来说,就是从海量数据中挖掘出有用的信息。 知识发现:从信息中获取有用的知识,筛选掉无用的信息。 数据清洗:从原始数据中清洗掉无用的数据,保留有效数据。 大数据:BigData ,大量数据,GB、TB。 1Byte = 8bit 1KB = 1024Byte 1MB = 1024KB 1GB = 1024MB 1TB = 1024GB 1P 2022-03-04 Hadoop大数据高级开发 Hadoop